
Building Semantically Rich Ontologies for Domain Models
A. Task Objectives
Ontologies are the natural vehicle for encoding unstructured knowledge into accessible structured domain knowledge that can be more easily integrated into a reasoning system. The objective of Building Semantically Rich Ontologies for Domain Models is to develop algorithms to: 1) use existing domain models to seed the process of extracting semantically rich ontology from unstructured text, 2) automatically update the ontology when new documents are made available or the domain model changes, 3) communicate ontology content across multiple applications using OWL/RDF as the common interchange format, and 4) allow the user to easily review, update, and maintain the ontology. Figure 1 illustrates the architecture of the proposed solution for automatic creation and management of semantically rich ontologies for domain models. The inputs to the system are one or more of any natural language documents, a short list of relevant domain seed concepts, and previously created ontologies that represent a domain model. The system generates ontologies with pointers back to the text documents from which the domain concepts and their relations are extracted.
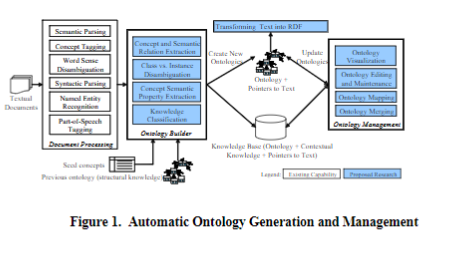
Lymba is uniquely qualified to accomplish this task due to its mature natural language processing (NLP) tools that extract semantic structure from unstructured documents and organizes them into an ontology. This technology has been developed in the last 10 years through Lymba’s participation in AQUAINT, NIMD, CASE, GALE and other research programs. The NLP tools include tokenization, part-of-speech tagging, named entities, events, syntactic parsing, and semantic relation extraction. During Building Semantically Rich Ontologies from Unstructured Text, Lymba proposes to extend this capability with algorithms that 1) use external third party domain models to guide the ontology extraction process, 2) align and merge both relations and concepts from external sources, 3) exploit RDF to encode the semantics in a W3C compliant format, and 4) allow users to modify and update the ontology. The result of this process is a knowledge base derived from a domain model that attaches contextual knowledge to the domain ontology. The underlying innovations include; 1) the use of Description Logic Tableau algorithms and structural subsumption for concept classification, 2) XWN-KB as the upper ontology extension to WordNet, 3) semantically rich ontologies that can be integrated with contextual knowledge to form a knowledge base and are built automatically, which makes them well suited for dynamic environments, and 4) encoding all semantic knowledge in RDF triples. Finally, Lymba will partner with Rockwell Collins to develop a robust framework to support the above tasks.Task 1: Extract Information Relevant to a Domain Model from Text
Lymba proposes to extract semantic information relevant to a domain model from text by developing algorithms that seed the ontology building process with the concepts and relationships encoded in the model. As documents are processed through the NLP tools, new concepts and semantic relations are discovered and added to the ontology based on a knowledge classification (subsumption) algorithms. In order to bootstrap the process Lymba will first develop algorithms for mapping domain model semantic relations into Lymba ontology relations. These algorithms will 1) process the target documents through the Lymba NLP tools, 2) identify concepts that are lexically similar to those in the domain ontology, 3) examine the semantic structure between the concepts in the document to the semantic structure between the concepts in the domain ontology to statistically link relations in the domain model with those identified in the text, 4) the candidate relation mapping will be presented to a user for confirmation. All Lymba relationships that do not match will still be added to the valid set of relations for the domain as they only add more semantic context for concept, which is useful for aligning concepts. Once the bootstrap relation mapping is complete, all the concepts and relationships extracted from the document set need to be filtered for relevance to the domain model. Lymba will develop algorithms to compute a domain model relevance score for each discovered concept based on the semantic distance from the original seed relations and concepts. The semantic distance is a function of the number and type of relations and concepts that are on the semantic path that links the original domain model concepts to the newly discovered candidate concept. Only concepts with a semantic distance score above a user selected threshold will be added to the domain ontology. In order to accommodate information added or deleted from the document set, Lymba will develop algorithms to track changes in the repository and update the information in the domain model.Task 2: Develop methods for ontology mapping and merging
When systems from different organizations interact, a common agreement of domain concepts and their attributes across ontologies is vital. Ontology mapping is the process of identifying a mapping, a set of rules, which link concepts from one ontology to their analogous concepts in another ontology. Lymba’s proposed method will derive SYNONYMY relations between the domain concepts of different ontologies using the semantic context associated with each concept, the lexical similarity of the concept, and the WordNet lexical chain computed from WordNet. Each candidate SYNONYMY relation will be assigned a confidence score that qualifies the strength of the relation found between the concepts being aligned. Our ontology mapping mechanisms rely on (1) the semantic representation of the domain concept, (2) its semantic context model, and (3) its definition or gloss.
The ontology merging process combines information from two or more ontologies into a new ontology. Once the mapping of the ontologies is complete, our proposed system will combine the domain concepts and the relations of the given ontologies to generate the resulting ontology. To ensure that the resulting ontology is logically and semantically consistent, we will develop algorithms that check for structural cycles as well as validate the semantic soundness of the ontology by consulting a semantic calculus.Task 3: Transforming Text into RDF
In order to make the semantics encoded in the ontologies built in Task 1 and Task 2 readily available to third party reasoning engines, Lymba will develop algorithms to map the semantic relations and the concepts into the W3C standard for the Resource Description Framework (RDF). Lymba already has a complete RDFS schema for the information extracted by it tools and would extend this to work with the information extracted for domain models.
Task 4: Integrating User based Ontology Manipulation and Review
Today Lymba has an ontology editing tool that visualizes the ontology and makes it possible to add, delete, and update relations and concepts. Lymba will extend this tool to track the owner, timestamp, and virtual location associated with the change. All changes made in the ontology editing tool will be database backed. To control the changes made to the live ontology, Lymba will develop an interface to only update the core ontology after the changes have been presented and reviewed by the maintainer. Once the changes are accepted, they will be propagated to the live system.
B. Technical Summary and Task Deliverables
Lymba has an extensive background in extracting semantics and ontologies from text. This background will be leveraged to solve the problems of extracting information relevant to a domain model, mapping and merging relations and concepts from different ontology sources into a common vocabulary, and integrating and maintaining changes to the ontology due to either changes in the source document repository or changes in the ontology structure via a user based tool. Because these ontologies will be encoded in RDF triples, the information can readily be exchanged between applications. The deliverables include: 1) Algorithms for extracting information relevant to a domain model, 2) Algorithms to map and merge concepts and relationships between different ontologies, 3) Algorithms to transform semantics encoded in the ontology and extracted from text into RDF triples, and 4) Methods to control and propagate updates made to the ontology.